-
[Python] BOJ 11728 배열 합치기코딩테스트/백준 2025. 2. 6. 16:46
https://www.acmicpc.net/problem/11728
요구사항
- 시간 제한: 1.5초
- 메모리 제한: 256MB
- 두 배열을 합쳐 정렬할 것
각 배열의 크기는 1,000,000 O(N log N )일 떄 약, 20,000,000 번
파이썬에서 정렬 sort() 의 시간 복잡도 O(N log N) 이 걸림. 따라서 만족
설계 1 (답안은 설계 3 참고)
- set 자료구조를 사용
- a | b 를 사용해 정답을 구한다.
import sys input =lambda: sys.stdin.readline().rstrip() size = map(int, input().split()) a = set(map(int, input().split())) b = set(map(int, input().split())) result = a | b print(*result)- 틀린 이유:
- 전 문제 영향을 받았다. 생각 없이 set을 사용함.
- union 즉 | 는 순서를 보장해주지 않는다. 즉, 매번 다른 결과 도출.
- 따라서 sorted(result)를 해주자.
설계 2
- 위 틀린 이유를 바탕으로 print(*sorted(result)) 하였음.
- 하지만, 틀렸다. (테스트 케이스는 다 맞아서 뭐가 문제인지 한참 고민함.)
- 문제를 다시 읽어보면 집합이 아닌 배열이라 명시하였음.
- 따라서 테스트케이스에서는 없지만 중복을 허용할 수 있다는 뜻으로 간주.
설계 3
- set 자료구조를 list로 바꾼다.
- union 을 사용하지 않고 + 연산자를 사용
import sys input =lambda: sys.stdin.readline().rstrip() size = map(int, input().split()) a = list(map(int, input().split())) b = list(map(int, input().split())) result = a + b print(*sorted(result))- 추가로 size라고 한 이유는 딱히 이 문제에서 사용하지 않아. 그냥 지은 것.
문제 하단의 알고리즘 분류 (feat. 정렬, 투 포인터)
투 포인터로 풀라는 거 같은 데 어떤 알고리즘일까?
n, m = map(int, input().split()) # 각 배열의 크기 a = list(map(int, input().split()) # 배열 A b = list(map(int, input().split()) # 배열 B result = [] # 결과 리스트 i, j = 0, 0 # 각 배열의 인덱스 while i < n and j < m: if a[i] <= b[j]: i += 1 result.append(a[i]) else: j += 1 result.append(b[j]) # 남은 원소들을 추가 (어느 한 쪽 배열이 먼저 끝난 경우) if i < n: result.append(a[i:]) if j < m: result.append(b[j:]) print(*result)- 위 알고리즘으로 문제를 풀 경우 기존 알고리즘(O(N log N) -> O(N + M) 으로 단축할 수 있다.
- 두 배열을 한 번만 스캔하면 되기 때문이다.
- 그리고 다시 정렬할 필요 없는 이유는 두 배열이 이미 정렬되어 있기 때문이다.
회고:
이론적으로 단축되어야 하는 데, 아래 사진을 보면 sorted() 했을 때, 오히려 시간이 단축된 것을 알 수 있다.
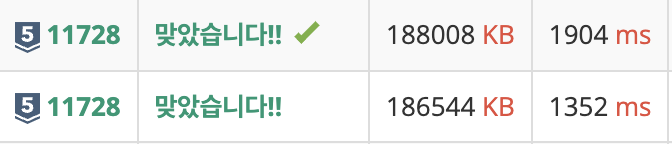
왜 이런 현상이 발생했을 까?
- sorted()를 사용한 코드는 두 리스트를 연결하여 새로운 리스트를 생성한다. 이 과정에서 메모리 할당이 한 번만 발생한다.
- 반면에 투 포인터를 사용한 코드는 result.append() 연산이 호출될 때마다 메모리를 재할당해야 할 수 있다. 메모리 재할당은 상대적으로 많은 시간을 소요하는 작업이다.
따라서 result = [] 와 같이 빈 리스트로 시작하는 대신, 초기 용량을 미리 설정하여 메모리 재할당 횟수를 줄여보자.
result = [] * (n + m)
맨 위: 초기 용량 미리 설정, 중간: 투포인터, 마지막: sorted() 초기 용량을 설정해준 결과 어느 정도 최적화를 한 것을 볼 수 있다. (현대 메모리 용량은 기술의 발전으로 크게 신경쓰지 않는 다길래 시간복잡도를 최적화하는 데만 신경써보자.)
투 포인터 알고리즘 소스코드의 마지막 부분(남은 원소들 모두 추가)에서 append()메서드를 사용하고 있다. 이 경우 extend() 메서드를 사용하는 것이 메모리 재할당 부분에서 더 효과적이다. 그 이유는 extend 메서드의 경우 여러 요소 한 번에 처리하여 메모리 재할당 횟수가 적기 때문이다. 하지만 우리의 경우 초기용량을 정확하게 알고 있는 경우 그 차이는 미미할 것으로 예상된다.
마지막으로 sys.stdout.write() 를 사용해보자. print(*result)는 리스트의 모든 요소를 문자열로 변환하여 출력한다. 이 과정에서 시간이 많이 소요될 수 있다. sts.stdout.write() 를 사용하면 문자열 변환 없이 직접 요소를 출력할 수 있다.
import sys for x in result: sys.stdout.write(str(x) + ' ') sys.stdout.write('\n')
- 시간이 단축 되었다. 하지만 여전히 적다. 왜 그런 지 모르겠다. 아마 sorted()는 C로 최적화되어 구현되어 있지 않을까? 따라서 알고리즘의 이론적 시간 복잡도는 더 높아 보이지만, 실제 구현에서는 느린 것이다.
회고:
이론적인 시간복잡도도 중요하지만, 만약 파이썬 내장함수를 알고 있다면 최대한 활용하는 것이 오히려 시간 복잡도를 줄일 수 있다.
'코딩테스트 > 백준' 카테고리의 다른 글
[Python] BOJ 9935 문자열 폭발 (0) 2025.02.20 [Python] BOJ 1406 에디터 (0) 2025.02.20 [Python] BOJ 1269 대칭차집합 (0) 2025.02.06 [Python] BOJ 8595 히든넘버 (0) 2025.02.03 [Python] BOJ 28278 스택 2 (0) 2025.02.02